
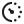


.png)

Rule engines are quietly doing heavy lifting in a lot of production systems. They let you separate business logic from application code — which sounds simple, but makes a huge difference when requirements keep changing. Among the different techniques for building them, Abstract Syntax Trees tend to come up often, especially when the rules get complex.
This guide walks through what ASTs are, how they're used in Java rule engines, and how to actually implement one. There's also a section on where things tend to get hard, because they do.
What is an Abstract Syntax Tree (AST) in Java?
An Abstract Syntax Tree is a hierarchical representation of an expression or piece of code. Not the raw text — the structure behind it. Each node in the tree represents something meaningful: an operator, a variable, a literal value. The edges show how those pieces relate to each other.
In Java, Abstract Syntax Trees are commonly used in compilers, expression evaluators, rule engines, and query parsers to represent code structure in a hierarchical tree format.
What makes ASTs useful isn't just that they're structured — it's that they're evaluable. You can traverse the tree, visit each node, and compute a result. That's what makes them good for rule engines.
Take a simple rule: price > 100 AND stock < 50
In AST form, it looks like this:
AND
/ \
price stock
> <
100 50
Each condition becomes a subtree. The root node holds the logical operator. Evaluation starts at the leaves and works upward.
One thing worth noting: ASTs are abstract. They strip away syntax details (parentheses, semicolons) and keep only the semantics. That's what makes them easier to evaluate programmatically.
Structure of an Abstract Syntax Tree in Java
Before getting into rule engines, it helps to understand what the actual node types look like. There are four you'll encounter most often:
Operator nodes — represent logical or arithmetic operations. AND, OR, +, >, ==. They have child nodes that represent their operands.
Literal nodes — hold constant values. The number 100, the string "active", a boolean true. No children. This is where evaluation bottoms out.
Variable nodes — hold references to runtime values. The variable price doesn't have a value until you supply a context at evaluation time.
Expression nodes — compound structures that combine the above. A comparison like price > 100 is technically an expression node with a variable node on the left and a literal node on the right.
Here's a minimal Java example showing how this works in practice:
This looks simple. It usually isn't — once you add variables, multiple data types, and nested logic, the node hierarchy grows quickly.
Read more about XML rule engine
How Abstract Syntax Trees Work in Java Rule Engines
Generally, in business rule engines, ASTs act as intermediaries between the textual representation of a rule (e.g., "price > 100") and its execution. The workflow typically involves:
- You write a rule as text: "price > 100 AND stock < 50"
- A parser reads the text and builds an AST
- The tree gets traversed — each node evaluated based on its type
- A final result comes out
That traversal step is where the actual logic lives. For a LogicalNode, evaluation might call left.evaluate() and right.evaluate() and then combine them with AND or OR. For a ValueNode, evaluation just looks up the variable in a context object.
This is called recursive evaluation — each node evaluates itself by asking its children to evaluate themselves first. It maps cleanly to the tree structure.
The other pattern worth knowing is the interpreter pattern. Instead of putting evaluate logic inside each node class, you use a separate visitor/interpreter that knows how to handle each node type. More verbose, but easier to extend.
Evaluating AST Expressions in Java
Here's the evaluation pipeline laid out clearly:
Expression (text)
↓
Parser
↓
AST Generation
↓
Tree Traversal
↓
Execution
The expression is raw text — a string like "age > 18 AND status == 'active'". The parser reads it token by token and checks whether the grammar holds. If it doesn't, nothing downstream works. From that, AST generation builds the actual tree structure — nodes representing operators, leaves representing values. Get operator precedence wrong here and the tree is silently wrong. Tree traversal walks that structure recursively; this is where deeply nested rules start to get expensive. And execution is where the tree meets real data — it needs the right context values present, or it fails quietly.
Each step has its own failure modes. Parsing breaks if the grammar isn't well-defined. AST generation can produce incorrect trees if operator precedence isn't handled right. Tree traversal can get expensive with deeply nested structures. Execution depends on having the right context values available.
The recursive evaluation approach works well for moderate complexity. For larger rule sets with thousands of nodes, you may want to look at memoization or short-circuit evaluation — where an AND condition stops evaluating once one operand is false.
Implementing a Rule Engine with AST in Java
Building a rule engine with Abstract Syntax Trees (AST) in Java rule engines involves several steps, from parsing rules into an AST structure to evaluating the tree to execute logic dynamically. This section provides a step-by-step guide to implementing a scalable AST rule engine.
Step 1: Define the AST Node hierarchy
Step 2: Build a Parser
In a real system, you'd use something like ANTLR. For illustration:
Step 3: Create a Context
Step 4: Run the Engine
From here, you'd want to extend this with real expression parsing (not hardcoded), support for arithmetic comparisons, and error handling for malformed rules.
Challenges in Building Rule Engines with AST
A few things tend to cause problems in practice.
Parsing is harder than it looks. Writing a robust parser that handles operator precedence, parentheses, and edge cases takes real effort. Most projects underestimate this.
Performance with large rule sets. Traversing deep trees repeatedly isn't free. If you're evaluating thousands of rules against high-frequency data, you'll need to think about caching and tree optimization.
Real-time data integration. Rules often need to pull values from external sources — APIs, databases, event streams. Wiring that into the context cleanly adds complexity.
Maintenance burden. Every time the business logic changes, someone has to modify the rule definitions, retest, and redeploy. With AST-based systems, that often means touching code.
Debugging. When a rule produces an unexpected result, tracing it through a tree isn't intuitive. Good logging at the node level helps, but it's extra work to set up.
This part often gets ignored during initial implementation. The parser works, the tests pass, and then six months later someone needs to add a NOT operator and the whole system needs rethinking.
Does Nected Use AST?
Not directly. Nected takes a different approach — visual Decision Tables and low-code workflows instead of tree construction and traversal.
The tradeoff is real. You lose some of the raw flexibility of hand-crafted ASTs, but you gain a lot in terms of maintainability and accessibility. Non-technical users can define and modify rules without touching code. Rule changes don't require redeployment. And built-in integrations mean you don't have to write your own data connectors.
For teams where business users need to own rule definitions, or where the overhead of building and maintaining a custom AST engine is too high, something like Nected makes sense. For teams with specific performance requirements or highly unusual rule structures, rolling your own might still be the right call.
How to Build Complex Rules in Nected (Without the AST Overhead)
If you want AST-level logic complexity without writing the AST yourself, Nected's Decision Tables are worth looking at.
The basic workflow:
- Define input attributes (price, demand, inventory_level)
- Write conditions in a tabular format
- Group conditions with AND/OR logic
- Specify what happens when conditions match
- Connect real-time data sources via API or database
- Test and deploy
Example Decision Table:
For more complex logic, Nected supports grouped conditions — essentially nested logic — and custom formulas for dynamic computation. It's not identical to a hand-built AST, but it covers most real-world use cases without the parser headaches.
For teams already exploring other rule engine approaches, there's also a good overview of rule engine design patterns, Python rule engines, and PHP workflow engines worth reading alongside this.
FAQs
What is an Abstract Syntax Tree in Java?
An AST is a tree-based representation of an expression or code block, where each node represents an operation, variable, or value. In Java, they're used in compilers, rule engines, expression evaluators, and query parsers to represent and process code structure programmatically.
How does AST evaluation work in Java?
Evaluation is recursive. Each node asks its child nodes to evaluate themselves first, then combines the results. A LogicalNode with an AND operator evaluates its left and right children and returns left && right. Leaf nodes (variables, literals) return values directly.
Why are ASTs used in rule engines?
Because they separate rule parsing from rule execution cleanly. Once a rule is in AST form, you can evaluate it against any context without re-parsing. They also handle nested conditions and complex logic well.
What is the difference between a parse tree and an AST?
A parse tree includes every syntactic detail — parentheses, semicolons, keywords. An AST strips those out and keeps only what matters for semantics. ASTs are smaller and easier to evaluate. For rule engines, ASTs are almost always what you want.
Can you build a rule engine without AST?
Yes. Some rule engines use flat condition lists, decision tables, or interpreted scripting. AST is one approach, not the only one. The right choice depends on your rule complexity and how dynamic the rules need to be.
What Java libraries help with AST-based rule engines?
ANTLR is commonly used for grammar-based parsing. MVEL and JEXL are expression language libraries that handle evaluation. For more complete rule engine frameworks, Drools is worth looking at, though it comes with significant overhead.
What is the role of AST in rule engines?
AST (Abstract Syntax Tree) provides a structured way to parse and evaluate rules dynamically. It represents the syntactic structure of rules, enabling systems to execute logic based on defined conditions and operations.
What are the advantages of using Nected over traditional AST-based rule engines?
Nected offers several advantages, including faster rule development, reduced maintenance complexity, real-time data integration, scalability, and ease of use. Unlike AST-based systems, Nected democratizes rule management, making it accessible and efficient for all users.




.svg.webp)
.webp)
.webp)







.webp)








%20(1).webp)
