
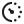
.webp)


.png)

Business logic just grows. You start with a couple of basic if statements. Six months later, it's a massive, nested mess of hardcoded thresholds. Usually, only one or two engineers even know how it works anymore (this is where things usually break).
The rules engine pattern is basically a way to rip that decision-making logic out of your core application so you can actually manage it.
What Is a Rule Engine Design Pattern?
Instead of baking rules into your compiled code, you keep them completely separate. An engine evaluates the rules, and the rules define the behavior. Neither messes with the other.
At its core, you just have an Evaluator. It loops through a set of rules. Each rule is nothing more than a condition and an action. If the condition matches the incoming data, it fires the action. The main app doesn't even need to know what rules exist or why.
This isn't just a refactoring trick to make your if/else chains look prettier. The rules live outside the application—usually in a database or some external config file. That means you can change them at runtime without kicking off a whole new deployment.
It comes in really handy when the same piece of data needs to trigger multiple different actions. Or when the business team wants to update the logic without begging a developer to write code.
Core pieces
The parts that make up an engine are pretty standard across different languages.
First is the Engine itself. It takes the input, checks the conditions, and triggers things. Then you have the rule collection, usually pulled from a central datastore.
The input is just facts. Runtime data like user attributes, system states, or transaction amounts. That's what the rules evaluate against.
Trigger conditions decide when a rule activates. Data comparisons, timestamps, external signals, whatever. If the condition is met, the Action happens. That action might just flip a boolean flag, or it might trigger a whole downstream microservice.
Under the hood, you'll sometimes see specific services just to evaluate certain types of triggers. This keeps the logic somewhat composable. A processing engine combines all the ANDs, ORs, and NOTs to figure out if the whole rule actually passes. Once it does, execution services carry out the actual work.
This looks simple. It usually isn't.
Also Read: Top Open Source Rule Engine
Rules Engine Architecture
The architecture of a rule engine is layered. Each layer has a distinct responsibility; they communicate through defined interfaces.
Rule Repository Where rules are stored and retrieved. Could be a relational database, a document store, a flat-file configuration, or a dedicated rule management system. The key requirement: rules must be retrievable at runtime without a deployment. If changing a rule requires a code push, the architecture isn't doing its job.
Rule Engine Core The central orchestrator. Loads rule definitions from the repository, manages the evaluation lifecycle, and coordinates between the inference engine and execution layer. This is the piece that most implementations get wrong — it ends up taking on too many responsibilities. A clean core should be narrow: receive facts, coordinate evaluation, return results.
Inference Engine Handles the logic evaluation. Takes the facts and the rule conditions and determines which rules match. Two evaluation strategies are common here. Forward chaining starts with the facts and works toward conclusions — standard for decision automation. Backward chaining starts with a goal and determines whether the facts support it — more common in expert systems. Most production rule engines use forward chaining.
Execution Layer Carries out the actions for rules that have fired. Separated from inference deliberately — evaluation and execution are different concerns and fail in different ways. An evaluation error means a rule didn't match correctly. An execution error means an action failed after a valid match. Keeping these separate makes debugging significantly less painful.
API Layer The interface through which the application interacts with the rule engine. Accepts facts as input, returns evaluation results or events. In microservice architectures, this is often a REST or gRPC endpoint. In embedded implementations, it's a library interface. The API layer is also where rule management operations are exposed — create, update, delete, version rules — for integration with admin interfaces.
Read Also: Top 7 Python Rule Engines for automating your task
Rule Engine System Design
System design for a rule engine looks different depending on where it sits in the architecture and what volume it needs to handle.
Embedded vs. standalone
An embedded rule engine runs inside the application process. Rules are loaded on startup or fetched on demand. Lower latency, simpler deployment, but the rule engine scales with the application and can't be independently managed or monitored.
A standalone rule engine runs as a separate service. The application makes calls to it via API. Higher latency per call, more deployment complexity, but the engine can scale independently, be versioned separately, and serve multiple applications. For organizations where rule logic is shared across several products, this is usually the right call.
State and persistence
Rule engines are stateless by design — each evaluation takes in facts and returns results without reference to prior evaluations. If your use case requires tracking state across evaluations (how many times a rule has fired for a given user, cumulative thresholds), that state lives outside the engine in a database or cache.
Performance considerations
Rule evaluation is generally fast for individual calls. Where it gets expensive is at scale — evaluating large rule sets against high-frequency input. Two optimizations matter here. Rete algorithm (used by Drools and similar engines) builds a network representation of the rule conditions that avoids redundant evaluation across overlapping conditions. Lazy fact loading defers fetching expensive data (external API calls, database lookups) until a rule actually needs it, rather than loading everything upfront.
Versioning
Rules change. Sometimes a rule change needs to apply immediately; sometimes it needs to be scheduled. Sometimes a bad rule update needs to be rolled back in minutes. The system design needs to account for rule versioning from the start — not retrofitted later. At minimum: rule versions should be immutable records, in-flight evaluations should complete against the version they started on, and rollback should be a first-class operation.
How a Rule Engine Works
The execution cycle, step by step:
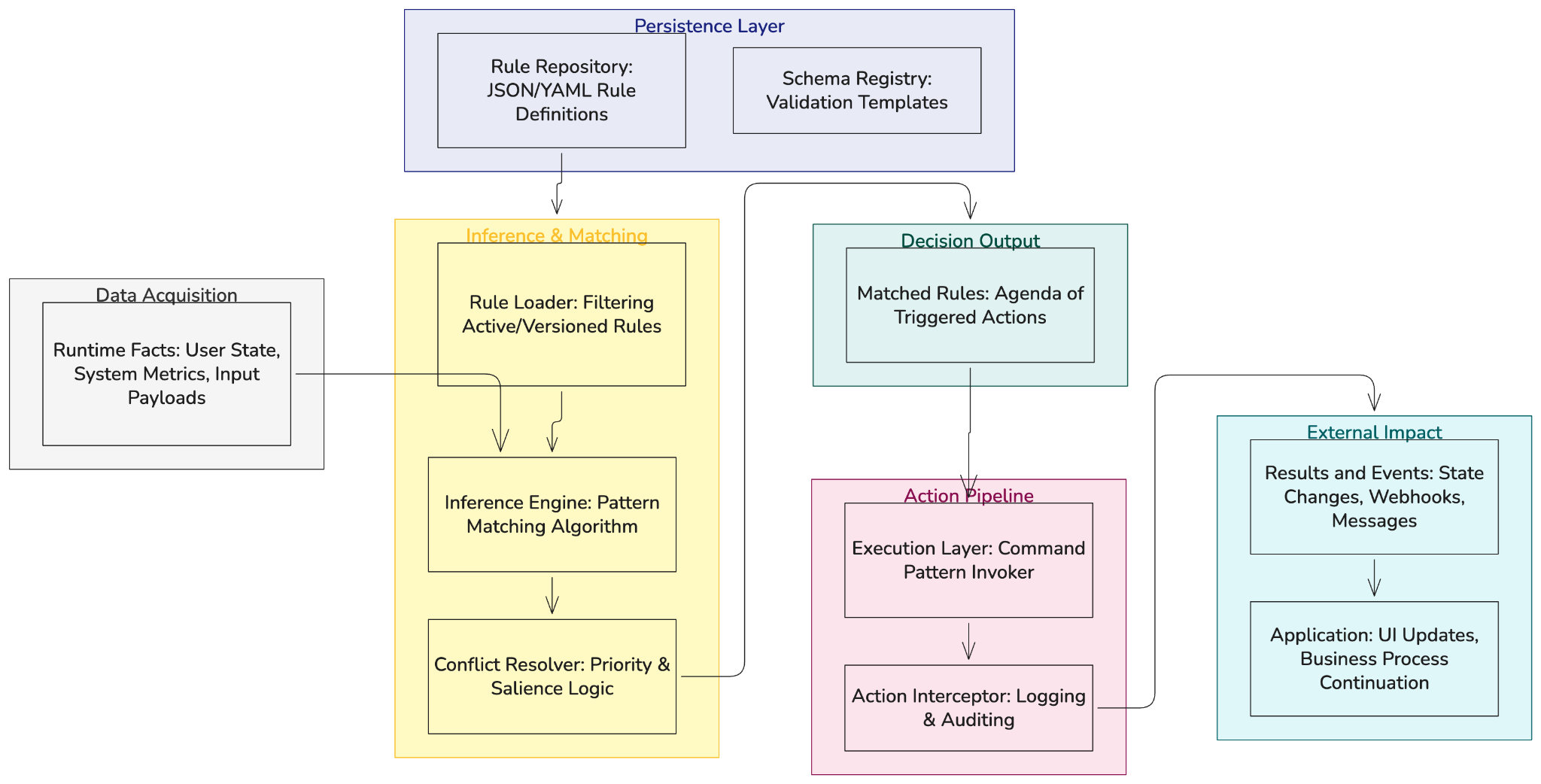
Each step can fail independently. Facts can be incomplete or malformed. Rule loading can fail if the repository is unavailable. Condition evaluation can error on unexpected data types. Actions can fail due to downstream system issues. A well-designed rule engine handles each failure mode explicitly rather than letting errors propagate silently.
Recursive evaluation
For rules with nested conditions — (A AND B) OR (C AND NOT D) — evaluation is recursive. The engine traverses the condition tree depth-first, evaluating sub-expressions before combining them at higher levels. The result at each node is a boolean that feeds into its parent node's evaluation.
Rule priority and conflict
When multiple rules match the same input, execution order matters. Most engines handle this through explicit priority values on rules (higher priority fires first) or through rule grouping (only one rule in a group fires, the highest-priority matching one). Without explicit conflict resolution, two rules firing on the same conditions can produce contradictory actions. This is one of the more common production bugs in rule engine implementations — and one of the harder ones to debug without good logging at the inference layer.
Also Read: Sprint Boot Rule Engines
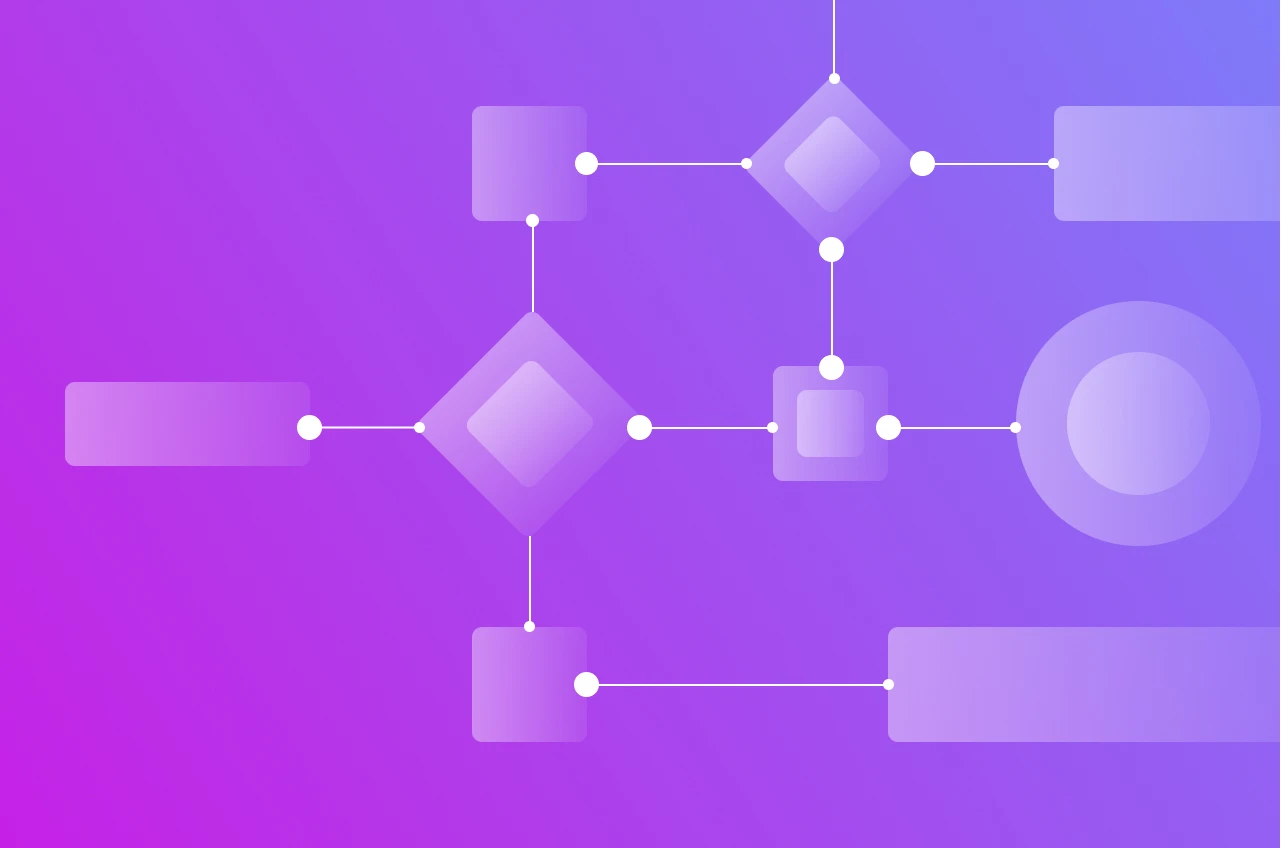
Rule Engine Architecture Diagram
A simplified view of how the layers connect:
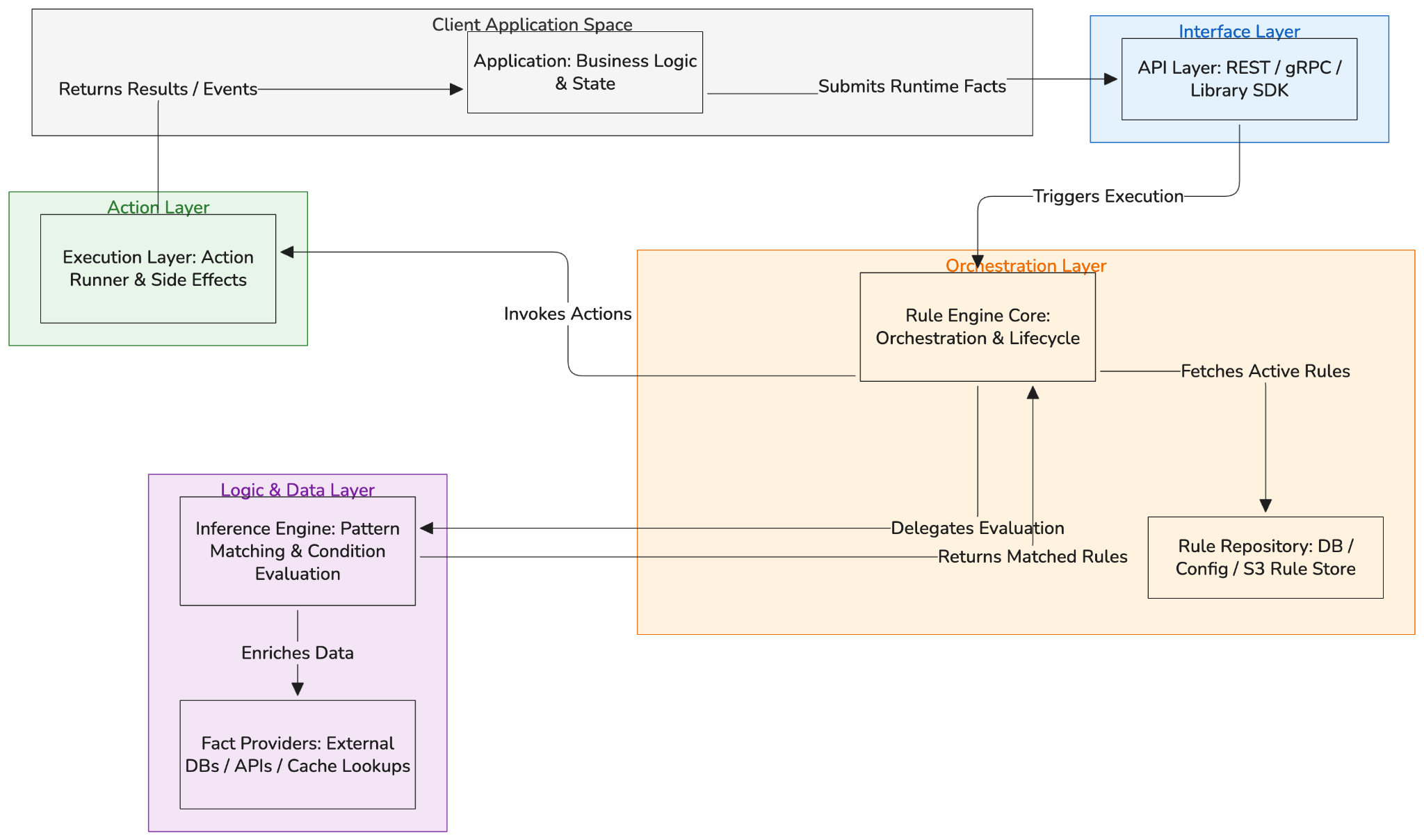
The API layer accepts facts and returns results. The core loads rules and coordinates. The inference engine determines which rules match. The execution layer runs the actions. Fact providers supply data lazily as the inference engine needs it.
Rule Engine Design Pattern Example
A concrete implementation — user permissions and access control — illustrates how the pattern works in practice.
The problem. An application has multiple user roles (admin, manager, employee, customer), each with different permissions. These permissions change as the product evolves. Hardcoding them means every permission change requires a deployment.
The rule-engine approach.
Define each permission check as a rule:
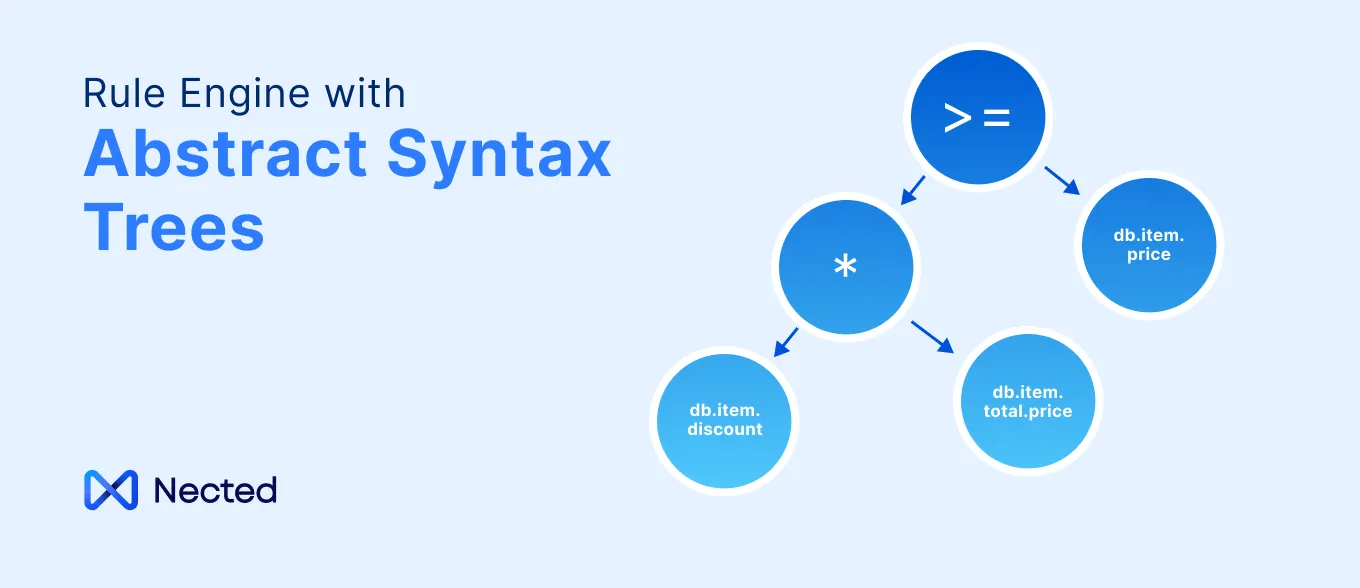
The rule says: if the user is a manager AND the resource is a purchase order AND the order value is under $50,000, grant approval permission. Changing the threshold from $50,000 to $75,000 is a rule update. No deployment required.
Step-by-step implementation
Define user roles and permissions. Organize them into a hierarchy — higher-level roles inherit lower-level permissions. Store this hierarchy as the foundation of your rule set.
Store rules externally. Database, configuration file, or a rule management system. The rules must be loadable at runtime.
Integrate the engine into the authorization path. When a user attempts an action, the application assembles the relevant facts (user role, resource type, resource attributes) and calls the rule engine. The engine returns events indicating which permissions were granted.
Build a management interface. Authorized administrators should be able to view and modify rules without touching code. This is where the operational value of the pattern becomes real.
Implement versioning. Track changes to rules. Make rollback possible. Maintain a history of modifications for audit purposes.
Test thoroughly. Rules with overlapping conditions interact in non-obvious ways. Testing individual rules in isolation is necessary but not sufficient. Integration tests that exercise multiple rules against the same fact sets are required to catch conflicts.
Advantages of Using a Rules Engine
Improved Maintainability
Externalizing rules creates a clear separation of concerns. Business logic changes don't require application code changes. The codebase stays stable while rule behavior evolves.
Enhanced Flexibility
Rules can be updated in real-time. No development cycle, no deployment window. For organizations that change business logic frequently — promotional pricing, eligibility criteria, fraud thresholds — this is a meaningful operational advantage.
Increased Agility
Business users can directly manage rules in many implementations. This removes IT from the critical path for rule changes, which matters in industries where requirements shift faster than development cycles allow.
Improved Scalability
A well-designed rule engine handles growing rule sets without degrading performance. As the number of rules increases, the architecture absorbs the complexity rather than pushing it back into the application.
Better Governance and Compliance
Centralized rule management means centralized auditing. Changes are tracked. History is preserved. Compliance requirements that demand documented decision logic are easier to satisfy when that logic lives in one place.
Implementation in Real-World Applications
Pricing and Promotions Management E-commerce platforms use rule engines to manage product pricing, discounts, and promotional conditions based on customer segments, inventory levels, and time-based triggers. The rules change constantly; externalizing them keeps marketing teams out of the deployment queue.
Loan Approval Workflows Financial services applications use rule engines to evaluate applicant data against predefined criteria. Conditions like credit score thresholds, debt-to-income ratios, and employment history checks are defined as rules. Regulatory changes translate to rule updates, not code changes.
Insurance Claim Processing Claim handling logic — coverage evaluation, deductible calculations, eligibility checks — is complex and changes with policy updates. Rule engines let insurers update claim processing logic without touching the core claims system.
Content Personalization Media and content platforms use rule engines to match users with content recommendations based on viewing history, preferences, and demographic signals. The targeting logic evolves continuously; rule engines make that evolution manageable.
Also Read: Workflow Rule Engine with PHP
Nected's Approach to Rule Management
Nected's rule engine supports multiple rule structures — rule sets, rule chains, and decision tables — allowing organizations to model business logic in whatever format fits the use case.
The engine integrates with external data sources directly: databases, APIs, and other endpoints can be connected to supply facts at evaluation time. Custom JavaScript is supported within rules for data transformation and advanced logic that doesn't fit standard condition operators.
Output formats include constants, JSON, and custom JavaScript formulas — results can be integrated directly into existing workflows and applications.
The no-code management interface lets business users create and modify rules without technical involvement. Versioning and auditing are built in: changes are tracked, history is maintained, and previous rule configurations can be restored.
For teams that want rule engine capabilities without building and maintaining the infrastructure themselves, this reduces the operational burden considerably.
FAQs
What is a rule engine design pattern?
A rule engine design pattern is a software architecture approach that externalizes business decision logic from application code. Rules are defined as conditions and actions, stored independently, and evaluated at runtime by an engine that receives input facts and fires matching rules. The pattern follows Single Responsibility — the engine processes; the rules define behavior.
What is rule engine architecture?
Rule engine architecture is the structural design of the components that make up a rule engine system. The key layers are the Rule Repository (where rules are stored), the Rule Engine Core (orchestration), the Inference Engine (condition matching), the Execution Layer (action running), and the API Layer (the interface for fact input and result output). These components are deliberately separated so each can fail, scale, and evolve independently.
How do rule engines work?
A rule engine accepts a set of facts — runtime data — and evaluates them against a collection of rules. Each rule has a condition and an action. The inference engine checks which conditions are satisfied by the current facts. For matching rules, the execution layer runs the associated actions. Results or events are returned to the calling application. The engine itself is stateless; state tracking for anything that needs to persist across evaluations lives outside the engine.
What is rule engine system design?
Rule engine system design refers to the architectural decisions about how a rule engine is deployed and integrated. Key decisions include embedded vs. standalone deployment, how facts are loaded and cached, how rules are versioned and rolled back, how rule conflicts are resolved, and how the engine scales under load. These decisions have significant operational consequences and are worth thinking through before implementation rather than after.
How does the rules engine design pattern differ from traditional if-else statements?
Traditional if-else statements embed decision logic directly in application code. Changing a condition requires a code change, review, and deployment. Rules in a rules engine are stored externally and evaluated dynamically — changing a rule is a data operation, not a code operation. Rules engines also handle scenarios where multiple conditions can match simultaneously and multiple actions need to fire, which gets increasingly difficult to manage cleanly with nested conditionals.
Can a rules engine be used in real-time decision-making?
Yes, and this is one of the primary use cases. Modern rule engines evaluate conditions fast enough for synchronous request-response flows — fraud detection, authorization checks, pricing calculations. The latency is typically in the low milliseconds for moderate rule set sizes. Performance degrades with very large rule sets or expensive fact lookups; both can be addressed through rule optimization and lazy fact loading.
How can a rules engine be integrated with machine learning models?
Rules and ML models solve different problems. Rules encode known, explicit logic — conditions you can write down. ML models handle patterns that are complex or implicit — conditions that emerge from data. The combination works well: the rule engine handles explicit business logic and compliance requirements; the ML model handles predictions or scoring. The rule engine then evaluates that score as a fact. For example, an ML model produces a fraud probability score; the rule engine fires an action if that score exceeds a defined threshold.
What are the considerations for choosing a rules engine technology?
Performance and scalability under your specific load profile. Integration compatibility with your existing stack. Rule management capabilities — versioning, auditing, management interfaces. Vendor or community support depending on whether you need formal SLAs. Licensing terms if you're embedding the engine in a commercial product. The last point is frequently overlooked and occasionally causes significant problems.
How can the rules engine design pattern be combined with other architectural patterns?
Microservices — the rule engine runs as a standalone service, independently scaled and deployed. Event-driven architecture — rule evaluation is triggered by events; results are published as new events. Layered architecture — the rule engine sits as a distinct layer between application logic and data. Plugin architecture — rule sets are loaded as plugins, allowing different rule configurations to be swapped without touching the engine itself.




.svg.webp)
.webp)







.webp)








%20(1).webp)
